|
����ǰ�� �������ٽ��й������꿪ʼ������ʽAI���ֳ�AIGC���ķ�չ��ν���á����ͽ�������ÿ�ܶ��������µ���Ϣ�ͳɹ����������͵��ż����õ�Ч�����ϳ��������֪����Խ��Խ�������֪������ʽAI�Ѿ���Ϊ�ƽ���һ�ּ������µ���Ҫ������ͬʱ��Ҳ��Խ��Խ����˿�ʼ˼��һЩ���⣬���磺Ϊʲô��õ�����Ч�������й����й�������ʽAI������ж�Զ��Ҫ������õ�����ʽAI������ģ�ͣ����ǻ���Ҫ������Щ������ ������������Ϊ������רע��������������˹������о���������17�����֮����ʼ��ע����ʽAI�ķ�չ����ؿ��ܣ���Щ�����ڹ�ȥ�ļ����ڲ������Ŷ��ڲ����ἰ�����ۣ�������һϵ�й����Ŀ�չ���ƽ������Ľ����������˶���Щ�����˼�����Լ���ǰ��һЩ��չ�� ������Ȼ����������ʽAI ������һ������ʽAI�ı�������Ҫ����Ȼ���Դ���������ͻ��˵��17��ȸ����Transformer�ܹ���ʹ�ü�������Ը��Ӹ�Ч�ؽ����ı�����֪ʶ��ѧϰ���Ӷ��ƶ�BERT��GPT��һЩ�д��ģ�ı�ģ�͵ĵ���������������ɵ�ά�ȶ�����˾�ͻ�ơ�����Ȼ���Դ���������������ͼ���������Ļ���ѧ�ƣ�Ҳ��Ϊ���������ı���ͼ����Ƶ����Ƶ����άģ�͵ȸ���ά������ʽAI�����ĺ��Ļ�����һ�������ǴӺ����Ļ��������ݵ�������������������ʽAIѵ�������ݣ�����һ����ͨ����Ȼ�������������ģ̬����Ϣ��ʹ����Щ֪ʶ���Ի�ͨ����Ҳ���ԺܺõĽ���ΪʲôӢ����̬�Ĺ�˾�ͻ�������һ�ּ����ȳ��и�����ռ���Ȼ� -- ��ǰ��ģ���������ḻ��������ߵĻ���ѧϰ��������Ӣ�Ĺ��ɵġ� ���������ı����������ݣ�Ӣ����������T0-SF��Muffin�ȴ������ʵ����ݼ���ͼ������Ҳ����LAION-2B��MSCOCO�ȿ�Դ���ݼ�������ڹ��ڣ�����������Ȼ������Ҳ�ж��������ݼ��Ľ��裬��200G����ı�Ԥѵ�����ݼ�������ա�1��ͼ�Ķ����ݼ��ȣ��������۴������������������ȣ��뺣������ݻ��Ǵ�����һ���IJ�ࡣ ��������֮�⣬Ӣ����̬����Ҳ�߱��dz���ȷ���������ƣ�������˴����������ֲ��߱������ʵ����ݡ�����˵ȫ������ѧ�����ġ���̴��롢�����ҵ����Ĺ淶������Щ������Ӣ�ĵĶ�������������ƣ�Ҳʹ�û���Ӣ����̬���о��������Ը��õ�ȥ�ƶ�����ء� ��������߳��������� ��������������������������ڵ��о��ߺͻ����ֲ�ȡ����Щ�취��������������4�ֲ��ԣ� ����1��ֱ���ÿ�Դģ�ͣ���API���� �������������ֱ�ӵķ�����������ͼ����������ȥ��stable diffusionģ�Ϳ�Դ֮������в��ٴ�ҵ��˾����ֱ�ӻ��ڸ�ģ�ͽ�������ѵ�����������ɣ�ͬʱ���� API�ķ���ӿڽ����ĵ�����ת����Ӣ��ʵ�ֶ������û���֧�֡�����·�ߵĺô��ǿ��Կ��ٵؽ����µ�Ӣ����̬�Ĺ���Ӧ�õ����ڡ�ȱ��Ҳ�dz����ԣ�һ���������ķ���������������ȱʧ���ܶ�Ӣ����������г��õ�˵�������ĵ�����û�а취�ܺõı���ģ�����˵�й�����������Լ����  ��������ֱ����ǧ�� from Mid Journel  ��������âЬ��ʤ�� from Mid Journel �����������ݵ��������Ҳ����ɵ��ص����ĵ�����������ʷ���ɣ��������ĵ�֪ʶȱ���ܺõ����⣬����˵�й�����ʷ�ż������ˡ���ʳ������ϰ�ס�  ������������ from midjournel  ������������ from mid journel ����������Ҳ������ĵ�һ�㣺���п�Դģ���������ݾݴ���ƫ�����Ϲ��ԺͰ�ȫ�Զ����з��ա�����˵����Щģ�������������ϲ�ƽ�ȣ�Ҳ���ڴ�����¶�����������ݡ�ֱ�ӽ���Щ����ģ�����ڹ��ڵ������������ž�����������Դ������ʼ����ز��Ŷ�����ʽAI���������ɼӴ���������ȡ� ����2���������ݷ��� �������ַ����ǵ�һ�ַ����ĸĽ��档�߱�һ���о������Ļ�������ѡ����������������֮�����Ӣ�ĵ����ĵķ��룬����Ӣ���������еijɹ����������ӿɿ�������ģ�ͣ�Ŀǰ�����в����о���������ҵ��ȡ������·�ߡ��ŵ��ǿ��Լ̳�Ӣ�ĵķḻ��������̬��ͬʱ���Զ���ơ����������ݽ���ϵͳ��ɸѡ�� ����ȱ�㻹�Ǵ���������죬������һЩ�ض������ı�������̬���Ļ�ϰ��ȱʧ���Լ����ݱ������Ǵ��зdz�ǿ��ƫ�������������ӡ���ʹȥ���˲��Ϲ�����ݣ���Щ���Ե�����Ǻ��ѽ���ġ����硰�����۵�Ů����������Ϧ���ա��ȵȡ� ����3���������ݹ��� ��������һ��������ߵĵ�·����Ҫ����ǰ�ڵĻ��ۡ����ݵ������Ĺ��������ڶ��������Ի�ó�Ч������Լ�ֵҲ���Ժ����������Ƶĸ��������ݵĽ��裬��������ʽAI���ڵĹ����ƽ������ɿ��������������ڷ������������۵��У���Ҳ���϶�Ϊ��һ������ȴ����ȷ�ĵ�·���Խ��������ݼ��ĺô����ڿ��Խ�����ij�����һϵ�л��������⣬�ֲ�ģ�Ͷ�����֪ʶ��Ƿȱ�����õ�ȥ�������ݰ�ȫ���Ӷ������ݵĺϹ��Խ�����Ч��ˡ� ��������ĿǰҲ��һЩ�����������ݹ�������Щ������������������������coco-cn��������������ʮ�����������١�wukong���ݼ���Ŀǰ�ϴ��ģ�Ŀ�Դͼ�����ݼ�������Ⱥ���ĶԱ����ݼ�Ŀǰ���Ǵ���һ����ࡣ���ೡ��֮�£���ص��о���ԱҲ��ʼ�������ڵ���������ҵ�����ƽ����������������ݼ��Ĺ���������Ҳ�������������ͬ�п�ʼ���뵽������С� ����4�������Լ��� �����Խ����ݼ���ã�����Ȼ���������������������ȱ�������⡣���Զ����Լ�����Ŀǰ���������ģԤѵ��ģ�ͼ����Ƚ���ʵ���еķ�������Ȼ���������Ŀǰ��������֤���У���ǰ�Ѿ���һЩ��صĹ�����ͨ�������Եķ�������Ӣ�ij�����ͼ�����⣬��ͼ���ɹ��ܣ���չ�������������У���ͨ��Ӣ����ϵ���������ֵ��ϰ��� ������ChatGPT��ѵ�����̵��У��Ѿ�����չ�ֳ������ԵĿ������Լ�DZ���������д����Ķ�Ԫ�����ںϣ�ĿǰGPT�����������Ѿ������ി����Ԥѵ��ģ���ӳ�ɫ����ͼ����������Nijiģ�͵Ŀ���������������Ч�����Dz����ġ� �������˵��ƾ�֮�� ����������ʽAI������Ч�����ǣ�����ѡ����һ���Ƚϳ��ڵļ���·�ߡ��ڼ��ݿ�Դ���ݵ�ͬʱ���ַ�Ϊ4���ƽ��������ǽ���������Ĵ��ģ�������ݼ�����ι��������������������ģ�ͣ�Ȼ��������ݼ�������ģ���ع�ͼ�������㷨�������������Ч�������������ר�Һ�����ķ�������ģ�������û�������Ҫ�ĸ��������ݡ� ����1��������ģ�������� ��������������������ţ����������𡢴�ý�������ֵȺ���ҵ���û���ҵ��ά���ṩ�����ݵ������������ɶ����������ݵĶ��壬��������ı�������ͼ�����۶ȣ���Ȩ�Ϲ����Լ��������������۱����Դ˿����ΪԼ����ͬ�ƽ����ݹ�����ͬʱ�����һ���ڷֲ�ʽ��������ݿ���ϵͳ����ר���ŶӸ����ṩ������������ģ�ͣ���ɹ�ͬ��ֺ��ٽ���������������ͳһ������ ����2�������������������ģ�� �������ڷ�������ǧ���ı�ģ�͵ļ������ۣ������ԡ�ϵ������ģ���Ⱥ�Ƕ�֪�����İ�FewCLUE��CLUE�������CLUE1.1�����������а�(����AFQMC[�ı����ƶ�]��TNEWS[���ı�����]��IFLYTEK[���ı�����]��OCNLI[��Ȼ��������]��WSC[��������]��CSL[�ؼ���ʶ��]6�����������ϳ�������ˮƽ������ϵ���еİ�������ģ����Ի�ģ������ɿ�Դ������ģ��Ҳ���ڽ��ڿ�Դ�� 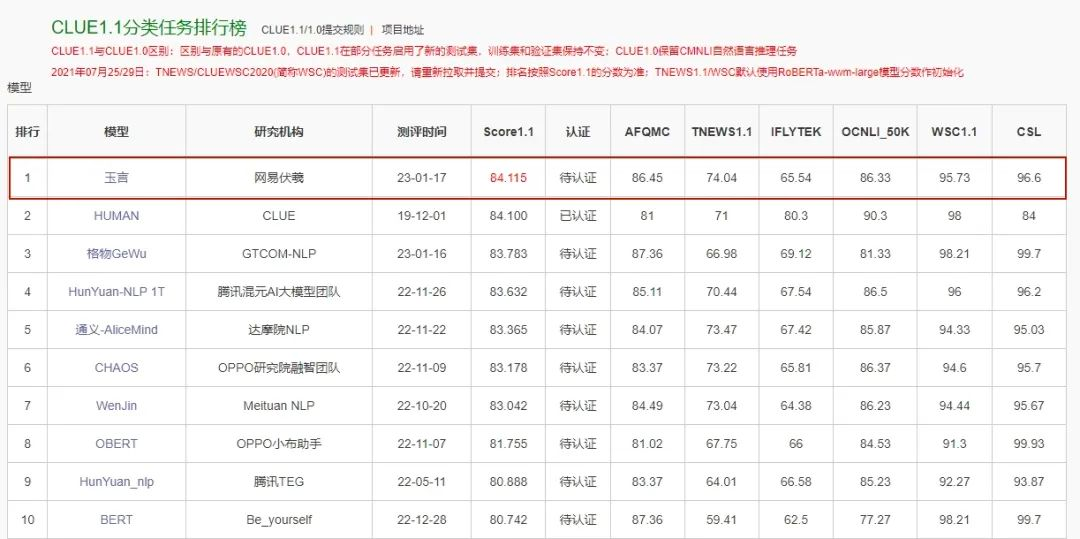 �������ı�����Ļ���֮�ϣ�������2021�����������조��֪����ģ̬ͼ�������ģ�ͣ�����ͼƬ-�ı�˫���ṹ��ģ�黯��ѵ��˼�룬�����ڼ��������ͼ�����ݶԣ��Ⱥ���������ֹ���ģ�Ͱ汾��������ͼ������ˮƽ�ϴﵽҵ������ˮƽ�����������õķ����ԣ������θ�����������࣬�������Ƽ��ȷ���������죻���ң���ͼ��ģ�͵�Ԥѵ�������У��������ͬ�ı����ȵ�ͼ�ĶԲ��ò�ͬ��ѵ�����ԣ���ʹ�á���֪��ģ�Ͷ�������н�ǿ������������ͬʱ�����������˿�Դ��EET��Ч������ܣ���ģ��ѹ�����㷨���䡢Ӳ���ײ�ȷ�������Ż���ʹ�������ٶ�����4�������������ϵĸ߲����������˲�����Դ����ġ�  ������ҵ�����ݼ���zero-shot������ ��������֪����ģ̬�����ģ������Chinese-CLIP��CN-CLIPViT-H/14 ������֪ģ��Ҳ�ɹ������Ķ��ҵ���еõ���֤����������Ѷ�����������ֵ��������Ƽ������ܱ�ע�ȳ�����������Ѷͨ��ͼ�Ĵ�ģ������ͼ�����ݱ��������Ƽ����ڲ��û��ڸ�ͼ��������dropoutnet�ٻ��Ż������ٻ�Դ���б�ҳ��Ƶ��Ͷ���б�ҳ��Ͷ�����Ч�����ԸĽ���ʵ����Ƶ��������̵�ҵ��ָ����������������ҵ�������ʹ�á�����������ͨ��ͼ�Ĵ�ģ���������ݱ���������������Ƽ������棬�ѳɹ�Ӧ������������Ƶ������Ƶ�����ȶ������ҵ������������Ч�ʡ�CTRԤ��ģ�͵ȣ������������������档ͬʱ��һ�����ϻ�Ϊ�Ŷӣ���ַ�����������ҵ���ݼ����ԣ��Զ�ģ̬ģ�ͽṹ�����Ż�����ѡ���ʱ����������ö��ѵ��ģʽ��������֪-���ģ�ͣ���һ���������������Ŀ�ģ̬����������������ơ� ����3��ͼ�������㷨�ع� ������ͼ������Ԥѵ��ģ�͵Ļ����ϣ����˽�һ���ƽ�������ͼ����ģ�͡��������ࡱ���з���һ��������ǿ����ͼ������ɢģ�͡���������ɢģ�͵�ԭ�����ڹ㷺�ģ�8�ڣ�ͼ��������ѵ���Դﵽ�Ϻõ����ɽ������ͬ�ڳ����Ļ�����ɢģ�͵���ͼ���ɷ������������е�ģ�ͻ��߱������ص㣺 ����ģ�ʹ��£���ͼ���ɵ������������dz�ǿ�������û������ı��ı��������������ڷ������еġ���֪��ģ���������ᄈ�µı�����������������ģ�������ij����¾��еij�ǿ����������������⣬��������ģ�ͻ������ı���ͼƬ�����ģ�ǿ��������ͼ�������ֵIJ������ã��ܹ����ı����õ�����ͼƬ�����ɣ�������ɵĽ��Ҳ���������û���ͼ�� ����ͼƬ��߶ȵ�ѵ�����ڹ㷺�����ݼ��У�����ģ���ڳ�ֿ���ͼƬ�IJ�ͬ�ߴ�����������⣬����ͬ�ߴ�ͷֱ��ʵ�ͼƬ���з�Ͱ���Ӷ����еĶ�߶�ѵ�����ڳ�ֱ�֤ѵ��ͼƬѵ���IJ�ʧ���ǰ���£����������ܶ����Ϣ������ģ���ܹ���Ӧ��ͬ�ֱ��ʵ����ɡ� �������ݲ��ԣ���ε�ѵ���ܹ���֤ģ�ͼȾ��й㷺�ԣ��ֱ�֤���ɽ������������ʼ�Σ�ʹ���ڼ���Ĺ㷺�ֲ������ݣ���ģ�Ͳ��������������Ͼ��й㷺�ԣ����Ժܺõ�����һЩ�������ʫ�䣬�������Ƭ����������ȵȡ�ͬʱ�����ɵĻ�����Ҳ���ж����ԣ��������ɶ��ַ����֮��Ľηֱ��ͼ�Ĺ����ȣ�ͼƬ�����ȣ�ͼƬ���۶ȵȶ�������������ɸѡ�����Ż��������������ɸ�����ͼƬ�� �������ij����³�ǿ���������������� �ܹ���������û������룬���ҷ��ظ��û���Ҫ�Ķ����������ڳ�����ʫ�����������ɾ߱�һ�����ơ�  �������Ķ����� & ������? �����ǵķ��㷺�������������Ȱ��Ķ���Ԫ���������ͳ��ɽˮ��������Լ�֪�����ҵ�������ȡ�     �������ij������������ƣ����������й�Ԫ�ص���Ʒ�������δ���Ů����ͳ�ѽڵȳ���      ����4���˻�Эͬ��ǿ�����ݱջ� ���������ڻ�����������ɸѡ�����ɱ���������ȱ�ݺͲ������������������˵�aop�ڰ����������ǴӲ�ͬ�Ƕ��������˹�����ѵ���Σ��˹��Ӷ��ά�ȵ�������ɸѡ��������������ͼ��ƥ�䡢�����۶����ݣ��Բ����Զ�����ȱʧ��������������ģ�ͻ�ø��õ�Ч����ͬʱ��������ģ�͵����ɽΣ�Ҳ�����˹��ķ�������ģ�͵���������������ͼƬ���۶Ƚ������֣�ɸѡ���������������ɵĽ��������ģ�͵�����������ʵ�����ݱջ�������������ģ�͵��������������������� 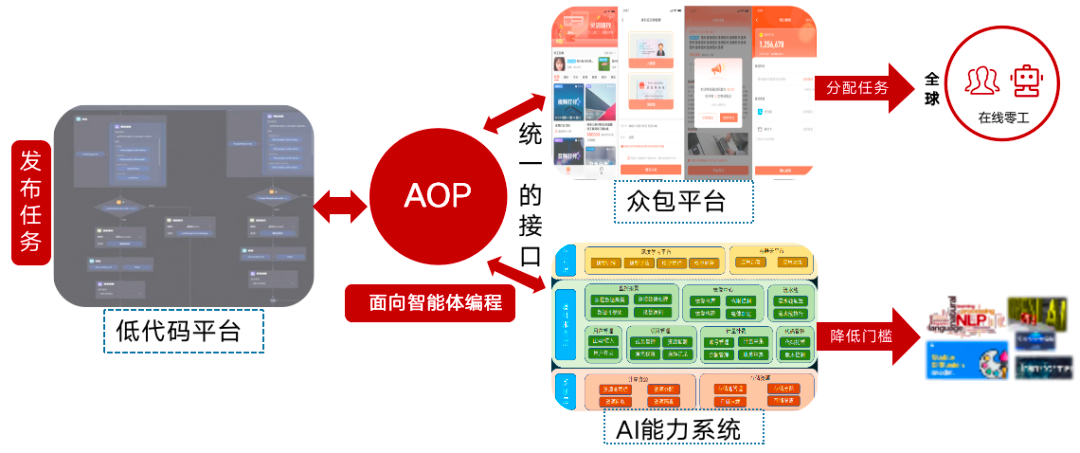  ��������������չ�� ���������ĸ�ά�ȵĽ��裬ʹ�������˵�ͼ������ʽAI�߱��Ϻõ��������⼰���۶ȱ������������������й��û���������Ϭ���Ĺ�����·�������˵�һ��������ʽAI�������µ���Ļ�ոտ�ʼ���������������IJ����ͷź��µĿ�Դ��̬����������ͨ�㷨�����ݡ��������˵Ĺ����ϻ��кܶ�����Ҫ�������˳����Ż�����Ч��������AI�ڽ������������еļ�ֵ������֪ʶ��Ȩ�ı�����AI�����Ĺ淶���ص�һЩ���⣬Ҳ��Ҫ������˼�������ơ� ����Ŀǰ�������������ƽ��������������ʽ�˹�����ƽ̨-������Լ���Ľ��裬��Я�ּ����ڲ���̬��ͬ�������������㷨ģ�͵���ƺ�ѵ����Ϊ��ҵ�û��ṩ��Ч�����䡢�ͳɱ�ģ�黯�ƶϡ���Դ��̬���ټ��ɡ�����ģ�Ͷ��Ƽ��ٵ��������������Ϊ���������ṩ�����������������ߣ�Ѱ�Ҹ��µ�������̬��Ϊ�ƶ�������������ͿƼ�����ע���µ������� |
�����ˣ�������ʽAI���й��û�������Ϭ
[�༭���¹�������]
���Ľ������������̼����߹۵㣬������Ҷ���������۵㣡